Something Broke!
Linux has come a long way since the days of non-existent wifi drivers and flash plugins. I dare say Linux is ready for non-technical users. At least I would say this if I didn’t still occasionally get random errors. You know, like this one:
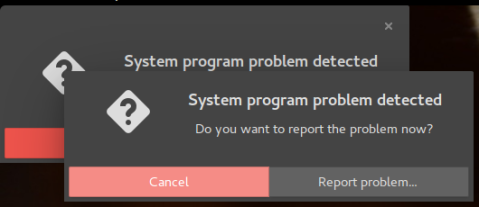
Awesome, something broke! Thanks for letting me know! Twice!
This one is a common one, and easily fixed. However, I never remember what the specific incantation for this one is, so I always have to Google it. But no more! Today I record the solution in my log!
The Solution
This one is caused by some process crashing. When a process crashes, apparently it dumps some junk into /var/crash that presumably the developer of said process knows about and cares about. Unfortunately I’m not said developer, and I don’t care about a one time crash of some random process. I do care that I’m getting 2-3 useless popups whenever I boot my Linux partition up. Let’s fix this:
NOTE: Consider looking in /var/crash to see what happened before randomly deleting all the stuff in it.
$ sudo rm /var/crash/*
$ sudo init 6After your machine reboots, you should be good to go.
The Specter of Undefined Behavior
If you’ve ever spoken to a programmer, and really got them on a roll, they may have said the words “undefined behavior” to you. Since you speak English, you probably know what each of those words mean, and can imagine a reasonable meaning for them in that order. But then your programmer friends goes on about “null-pointer dereferencing” and “invariant violations” and you start thinking about cats or football or whatever because you are not a programmer.
I often find myself being asked what it is that I do. Since I’ve spent the last few years working on my Computer Science degree, and have spent much of that time involved in programming language research, I often find myself trying to explain this concept. Unfortunately, when put on the spot, I usually am only able to come up with the usual sort of explanation that programmers use among themselves: “If you invoke undefined behavior, anything can happen! Try to dereference a null pointer? Bam! Lions could emerge from your monitor and eat your family!” Strictly speaking, while I’m sure some compiler writer would implement this behavior if they could, it’s not a good explanation for a person who doesn’t already kind of understand the issues at play.
Today, I’d like to give an explanation of undefined behavior for a lay person. Using examples, I’ll give an intuitive understanding of what it is, and also why we tolerate it. Then I’ll talk about how we go about mitigating it.
Division By Zero
Here is one that most of us know. Tell me, what is 8 / 0? The answer of course is “division by zero is undefined.” In mathematics, there are two sorts of functions: total and partial. A total function is defined for all inputs. If you say a + b, this can be evaluated to some result no matter what you substitute for a and b. Addition is total. The same cannot be said for division. If you say a / b, this can be evaluated to some result no matter what you substitute for a and b unless you substitute b with 0. Division is not total.
If you go to the Wikipedia article for division by zero you’ll find some rationale for why division by zero is undefined. The short version is that if it were defined, then it could be mathematically proven that one equals two. This would of course imply that cats and dogs live in peace together and that pigs fly, and we can’t have that!

However, there is a way we can define division to be total that doesn’t have this issue. Instead of defining division to return a number, we could define division to return a set of numbers. You can think of a set as a collection of things. We write this as a list in curly braces. {this, is, a, set, of, words} I have two cats named Gatito and Moogle. I can have a set of cats by writing {Gatito, Moogle}. Sets can be empty; we call the empty set the null set and can write it as {} or using this symbol ∅. I’ll stick with empty braces because one of the things I hate about mathematics is everybody’s insistence on writing in Greek.
So here is our new total division function:
totalDivide(a, b)
if (b does not equal 0)
output {a / b}
otherwise
output {}
If you use totalDivide to do your division, then you will never have to worry about the undefined behavior of division! So why didn’t Aristotle (or Archimedes or Yoda or whoever invented division) define division like this in the first place? Because it’s super annoying to deal with these sets. None of the other arithmetic functions are defined to take sets, so we’d have to constantly test that the division result did not produce the empty set, and extract the result from the set. In other words: while our division is now total, we still need to treat division by zero as a special case. Let us try to evaluate 2/2 + 2/2 and totalDivide(2,2) + totalDivide(2,2):
1: 2/2 + 2/2
2: 1 + 1
3: 2
Even showing all my work, that took only 3 lines.
1: let {1} = totalDivide(2,2)
2: let {1} = totalDivide(2,2)
3: 1 + 1
4: 2
Since you can’t add two sets, I had to evaluate totalDivide out of line, and extract the values and add them separately. Even this required my human ability to look at the denominator and see that it wasn’t zero for both cases. In other words, making division total made it much more complicated to work with, and it didn’t actually buy us anything. It’s slower. It’s easier to mess up. It has no real value. As humans, it’s fairly easy for us to look at the denominator, see that it’s zero, and just say “undefined.”
Cartons of Eggs
I’m sure many of you have a carton of eggs in your fridge. Go get me the 17th egg from your carton of eggs. Some of you will be able to do this, and some of you will not. Maybe you only have a 12 egg carton. Maybe you only have 4 eggs in your 18 egg carton, and the 17th egg is one of the ones that are missing. Maybe you’re vegan.
A basic sort of construct in programming is called an “array.” Basically, this is a collection of the same sort of things packed together in a region of memory on your computer. You can think of a carton of eggs as an array of eggs. The carton only contains one sort of thing: an egg. The eggs are all packed together right next to each other with nothing in between. There is some finite amount of eggs.

If I told you “for each egg in the carton, take it out and crack it, and dump it in a bowl starting with the first egg”, you would be able to do this. If I told you “take the 7th egg and throw it at your neighbor’s house” you would be able to do this. In the first example, you would notice when you cracked the last egg. In the second example you would make sure that there was a 7th egg, and if there wasn’t you probably picked some other egg because your neighbor is probably a jerk who deserves to have his house egged. You did this unconsciously because you are a human who can react to dynamic situations. The computer can’t do this.
If you have some array that looks like this (array locations are separated by | bars | and * stars * are outside the array) ***|1|2|3|*** and you told the computer “for each location in the array, add 1 to the number, starting at the first location” it would set the first location to be 2, the second location to be 3, the third location to be 4. Then it would interpret the bits in the location of memory directly to the right of the third location as a number, and it would add 1 to this “number” thereby destroying the data in that location. It would do this forever because this is what you told the machine to do. Suppose that part of memory was involved in controlling the brakes in your 2010 era Toyota vehicle. This is obviously incredibly bad, so how do we prevent this?
The answer is that the programmer (hopefully) knows how big the array is and actually says “starting at location one, for the next 3 locations, add one to the number in the location”. But suppose the programmer messes up, and accidentally says “for the next 4 locations” and costs a multinational company billions of dollars? We could prevent this. There are programming languages that give us ways to prevent these situations. “High level” programming languages such as Java have built-in ways to tell how long an array is. They are also designed to prevent the programmer from telling the machine to write past the end of the array. In Java, the program will successfully write |2|3|4| and then it will crash, rather than corrupting the data outside of the array. This crash will be noticed in testing, and Toyota will save face. We also have “low level” programming languages such as C, which don’t do this. Why do we use low level programming languages? Let’s step through what these languages actually have the machine do for “starting at location one, for the next 3 locations, add one to the number in the location”: First the C program:
NOTE: location[some value] is shorthand for “the location identified by some value.” egg_carton[3] is the third egg in the carton. Additionally, you should read these as sequential instructions “first do this, then do that” Finally, these examples are greatly simplified for the purposes of this article.
1: counter = 1
2: location[counter] = 1 + 1
3: if (counter equals 3) terminate
4: counter = 2
5: location[counter] = 2 + 1
6: if (counter equals 3) terminate
7: counter = 3
8: location[count] = 3 + 1
9: if (counter equals 3) terminate
Very roughly speaking, this is what the computer does. The programmer will use a counter to keep track of their location in the array. After updating each location, they will test the counter to see if they should stop. If they keep going they will repeat this process until the stop condition is satisfied. The Java programmer would write mostly the same program, but the program that translates the Java code into machine code (called a compiler) will add some stuff:
1: counter = 1
2: if (counter greater than array length) crash
3: location[counter] = 1 + 1
4: if (counter equals 3) terminate
5: counter = 2
6: if (counter greater than array length) crash
7: location[counter] = 2 + 1
8: if (counter equals 3) terminate
9: counter = 3
10: if (counter greater than array length) crash
11: location[count] = 3 + 1
12: if (counter equals 3) terminate
As you can see, 3 extra lines were added. If you know for a fact that the array you are working with has a length that is greater than or equal to three, then this code is redundant.
For such a small array, this might not be a huge deal, but suppose the array was a billion elements. Suddenly an extra billion instructions were added. Your phone’s processor likely runs at 1-3 gigahertz, which means that it has an internal clock that ticks 1-3 billion times per second. The smallest amount of time that an instruction can take is one clock cycle, which means that in the best case scenario, the java program takes one entire second longer to complete. The fact of the matter is that “if (counter greater than array length) crash” definitely takes longer than one clock cycle to complete. For a game on your phone, this extra second may be acceptable. For the onboard computer in your car, it is definitely not. Imagine if your brakes took an extra second to engage after you push the pedal? Congressmen would get involved!

In Java, reading off the end of an array is defined. The language defines that if you attempt to do this, the program will crash (it actually does something similar but not the same, but this is outside the scope of this article). In order to enforce this definition, it inserts these extra instructions into the program that implement the functionality. In C, reading off the end of an array is undefined. Since C doesn’t care what happens when you read off the end of an array, it doesn’t add any code to your program. C assume you know what you’re doing, and have taken the necessary steps to ensure your program is correct. The result is that the C program is much faster than the Java program.
There are many such undefined behaviors in programming. For instance, your computer’s division function is partial just like the mathematical version. Java will test that the denominator isn’t zero, and crash if it is. C happily tells the machine to evaluate 8 / 0. Most processors will actually go into a failure state if you attempt to divide by zero, and most operating systems (such as Windows or Mac OSX) will crash your program to recover from the fault. However, there is no law that says this must happen. I could very well create a processor that sends lions to your house to punish you for trying to divide by zero. I could define x / 0 = 17. The C language committee would be perfectly fine with either solution; they just don’t care. This is why people often call languages such as C “unsafe.” This doesn’t mean that they are bad necessarily, just that their use requires caution. A chainsaw is unsafe, but it is a very powerful tool when used correctly. When used incorrectly, it will slice your face off.
What To Do
So, if defining every behavior is slow, but leaving it undefined is dangerous, what should we do? Well, the fact of the matter is that in most cases, the added overhead of adding these extra instructions is acceptable. In these cases, “safe” languages such as Java are preferred because they ensure program correctness. Some people will still write these sorts of programs in unsafe languages such as C (for instance, my own DMP Photobooth is implemented in C), but strictly speaking there are better options. This is part of the explanation for the phenomenon that “computers get faster every year, but [insert program] is just as slow as ever!” Since the performance of [insert program] we deemed to be “good enough”, this extra processing power is instead being devoted to program correctness. If you’ve ever used older versions of Windows, then you know that your programs not constantly crashing is a Good Thing.

This is fine and good for those programs, but what about the ones that cannot afford this luxury? These other programs fall into a few general categories, two of which we’ll call “real-time” and “big data.” These are buzzwords that you’ve likely heard before, “big data” programs are the programs that actually process one billion element arrays. An example of this sort of software would be software that is run by a financial company. Financial companies have billions of transactions per day, and these transactions need to post as quickly as possible. (suppose you deposit a check, you want those funds to be available as quickly as possible) These companies need all the speed they can get, and all those extra instructions dedicated to totality are holding up the show.
Meanwhile “real-time” applications have operations that absolutely must complete in a set amount of time. Suppose I’m flying a jet, and I push the button to raise a wing flap. That button triggers an operation in the program running on the flight computer, and if that operation doesn’t complete immediately (where “immediately” is some fixed, non-zero-but-really-small amount of time) then that program is not correct. In these cases, the programmer needs to have very precise control over what instructions are produced, and they need to make every instruction count. In these cases, redundant totality checks are a luxury that is not in the budget.
Real-time and big data programs need to be fast, so they are often implemented in unsafe languages, but that does not mean that invoking undefined behavior is OK. If a financial company sets your account balance to be check value / 0, you are not going to have a good day. If your car reads the braking strength from a location off to the right of the braking strength array, you are going to die. So, what do these sorts of programs do?
One very common method, often used in safety-critical software such as a car’s onboard computer is to employ strict coding standards. MISRA C is a set of guidelines for programming in C to help ensure program correctness. Such guidelines instruct the developer on how to program to avoid unsafe behavior. Enforcement of the guidelines is ensured by peer-review, software testing, and Static program analysis.
Static program analysis (or just static analysis) is the process of running a program on a codebase to check it for defects. For MISRA C, there exists tooling to ensure compliance with its guidelines. Static analysis can also be more general. Over the last year or so, I’ve been assisting with a research project at UCSD called Liquid Haskell. Simply put, Liquid Haskell provides the programmer with ways to specify requirements about the inputs and outputs of a piece of code. Liquid Haskell could ensure the correct usage of division by specifying a “precondition” that “the denominator must not equal zero.” (I believe that this actually comes for free if you use Liquid Haskell as part of its basic built-in checks) After specifying the precondition, the tool will check your codebase, find all uses of division, and ensure that you ensured that zero will never be used as the denominator.
It does this by determining where the denominator value came from. If the denominator is some literal (i.e. the number 7, and not some variable a that can take on multiple values), it will examine the literal and ensure it meets the precondition of division. If the number is an input to the current routine, it will ensure the routine has a precondition on that value that it not be zero. If the number is the output from some other routine, it verifies that the the routine that produced the value has, as a “postcondition”, that its result will never be zero. If the check passes for all usages of division, your use of division will be declared safe. If the check fails, it will tell you what usages were unsafe, and you will be able to fix it before your program goes live. The Haskell programming language is very safe to begin with, but a Haskell program verified by Liquid Haskell is practically Fort Knox!
The Human Factor
Humans are imperfect, we make mistakes. However, we make up for it in our ability to respond to dynamic situations. A human would never fail to grab the 259th egg from a 12 egg carton and crack it into a bowl; the human wouldn’t even try. The human can see that there is only 12 eggs without having to be told to do so, and will respond accordingly. Machines do not make mistakes, they do exactly what you tell them to, exactly how you told them to do it. If you tell the machine to grab the 259th egg and crack it into a bowl, it will reach it’s hand down, grab whatever is in the space 258 egg lengths to the right of the first egg, and smash it on the edge of a mixing bowl. You can only hope that nothing valuable was in that spot.
Most people don’t necessarily have a strong intuition for what “undefined behavior” is, but mathematicians and programmers everywhere fight this battle every day.
As The Dust Settles
Rumors are swirling that Windows 8’s days are numbered. Windows 9 will allegedly be officially unveiled as soon as next month, and with it many of the changes in Windows 8 are being reverted. The start menu is back, Modern UI applications can run in a window, and the charms menu is dead.
All throughout the land, the people cheer! The beast is dead! A new age of enlightenment is upon us! Yet, amid the celebration, there stands a man who doesn’t look so cheerful. While the rest of the kingdom toasts the demise of Windows 8, I think of what could have been.
Don’t get me wrong: Windows 8 was terrible. In fact, Windows 8 was so bad that it drove me to abandon Windows and switch to Linux full-time. The fact that Microsoft has so radically changed their course is a good thing; a little humility will do them good. However, Windows 8 had a lot of innovative ideas. They may have had implementation issues, but most of these so-called anti-features could have been great. Unfortunately, the little failures that ruined the experience has taught the industry the wrong lesson. The industry’s takeaway from this fiasco is “people don’t want this.” However, I believe the less on to be learned is “if you’re going to change something, it must be perfect.”
Today, I’d like to talk about some of the innovative features of Windows 8; why I think they are great, and what I think went wrong.
The “Modern UI”
Since the dawn of the Graphical User Interface, we’ve used what is known as a “desktop metaphor.” The idea is that at the bottom, we have a desktop. On this desktop, we can put various things. We can put programs on our desktop, much like we put pens and paper clips and such. We can have “windows” open, much like the papers we write on. You know this story, you are probably reading this in a browser that is a window open on your computer. Tell me, when is the last time you got any actual work done with this window configuration?

I’m going to go with “never”. Sure this has probably happened to you, but I’m guessing you quickly maximized a window and restored order. If you do work with multiple windows, you probably arranged them like this:
…or maybe like this:

I’ve always been a fan of this configuration myself:

You most likely painstakingly arrange your windows so that they use the most screen real estate possible, except in cases where the program can’t use the space:

So, what’s the point? The only real thing we gain out of this arrangement is familiarity. Humans are by nature resistant to change. Something may be better, but it’s different and that scares us. But there are other options than the desktop metaphor. While there are few mainstream examples, tiling window managers offer a different take.
In a tiling window manager, windows cannot overlap. A window will take up as much space as possible, and if multiple windows are visible, the window manager will lay them out next to each other in various configurations. Since the window manager handles resizing and such, there is no need for window decorations and sizing controls.
The problem with these is the fact that they are hard to use. They require a lot of keybindings, and extensive config file editing. They fall squarely in the “fringe” of software. There is one mainstream tiling window manager though: the Windows Modern UI, formerly known as “Metro.”
When a Modern UI application is launched, it will become full-screen by default. You can then “snap” applications into up to four vertical columns, depending on your screen resolution. You can then do some simple window arrangement and sizing with your mouse. Unfortunately, while traditional tiling window managers are needlessly arcane and complex, the Modern UI is overly simplistic. You are limited to the one arrangement.
But the real problem is much bigger. This will be a recurring theme, but the main issue with the Modern UI is the fact that legacy applications don’t use it. Nobody tried it because none of their applications used it, therefore they never got used to it. Since none of their applications use the Modern UI, the Modern UI is, by default, “bad.”
Even Microsoft’s own software by-and-large didn’t use the Modern UI. The vast majority of Microsoft’s software that shipped with Windows 8 uses the traditional windowing system. To this day there is not a version of Microsoft Office that uses the Modern UI. Of the software that used the Modern UI, it tended to lack functionality. The Modern UI versions of OneNote and Skype have vastly reduced functionality compared to their desktop equivalents. It also didn’t help that most of the Modern UI applications that shipped with windows had banner ads baked in!
What do I propose? It seems simple to me: eliminate the desktop. Get rid of it period. All traditional desktop applications now run within a Modern UI window. They lose their window decorations, and can be closed using the standard method of grabbing the top of the window and dragging it to the bottom. If the application shows child windows, these windows will be displayed within the frame of the parent application with window decorations. These windows cannot be dragged outside the frame they are shown in. In effect, the application becomes its own desktop.
The Start Screen
Gone from Windows 8 is the start menu. Since Windows 95, there has been a little “Start” button on the bottom left corner of any Windows desktop. When pressed, it displays a little menu with all your programs displayed in a convoluted tree structure. If told me you’ve never seen an incarnation of this, I’d call you a liar; it’s that ubiquitous. Around the time of the introduction of the Start Menu was the introduction of keyboards with a special “Windows” key. The purpose of this key is primarily to show the start menu, so you don’t even need to click the button.
The Start Menu is gone in Windows 8. In its place is the start screen. The Start Button was also removed completely in Windows 8, but brought back due to popular demand in Windows 8.1. In Windows 8.1, if you click the Start Button the Start Screen is shown.
The Start Screen is basically a full-screen Start Menu. However, the tree is hidden, and instead you get a more tablet-like arrangement of your programs. This is shown as a grid of “tiles” that function as souped-up icons. These tiles can dynamically show information of a program’s choosing. A photo gallery application might show a mini slide show. A news application might show headlines. An e-mail application can show incoming messages.
I’m sure somebody will try, but I don’t believe a reasonable person can argue that these tiles aren’t an improvement on the old arrangement. Screen resolutions have gone up since the advent of icons, and it’s about time we put it to use. However, the problem with tiles is that their functionality is limited to Modern UI applications.
Granted, work would have to be done to update a traditional application to make use of the dynamic tile functionality, but there’s no reason it couldn’t be done. It would be quite easy to do. Unfortunately, Microsoft arbitrarily decided that only Modern UI applications should have access to this functionality. Traditional UI applications don’t even look the same:

On the bottom right, you’ll see some traditional applications, surrounded by nice pretty tiles. Those icons are forever doomed to be static and ugly because Microsoft wills it.
Charms Bar
Of all the things I’ve talked about, this is actually the one I’m most disappointed about. Live tiles live on in Windows 9, and I suspect the Modern UI tiling window manager will live in Windows RT. However, the Charms Bar is just dead. The Charms Bar is, in my opinion, the most innovative feature of Windows 8, and it is dying sad and alone because nobody understands it. You may even be wondering what I’m talking about. The Charms Bar is this thing:

You most likely recognize it as that annoying bar that pops up and gets in your way when you try to close a maximized program. It’s notable for doing seemingly nothing. Maybe you figured out that the shutdown option is hidden in there. The Charms Bar is actually amazing! …in theory. In practice it’s hampered by the fact that it’s tied to the Modern UI. Let’s talk about what this thing actually does.
Search
The Search charm is a context-aware search feature. If you’re sitting at the Start Screen, it functions as your standard Windows search. But if you’re in a Modern UI application? In this case, the search charm does whatever the application wants it to. In a text editor it may search the document for a string. If you’re in an instant messenger it might search your buddy list. If you’re in an e-mail application it might search your inbox for a message.
The Search charm, as with all the charms is controlled by the active application. The idea is that no matter what you’re doing, if you want to search, the function will always be located within the Search charm. This provides a consistent way to search across all applications!
Share
The unfortunately named Share charm isn’t actually about posting to Facebook. That said, posting to Facebook is a valid use of the Share charm. The Share charm is a context-aware way to send data to another application. An image editing application might be able to send an image via email, or post it online via Facebook. To do this, you could use the Share charm, and select the appropriate application. Similarly, an email program could support opening an image in an image editor via the Share charm. The Share charm is all about outputting data to other applications, and can almost be seen as a fancy graphical version of the UNIX pipe!
Start
The Start charm is just the Start Button. It was never gone, just moved.
Devices
The idea here is similar to the Share charm. The Devices charm allows you to interact with any appropriate hardware device. An image editor might list cameras (to import images), scanners (to scan images), and printers (to print images) here. A remote controlling application might show a saved list of computers to access here. A slide show application might show projectors here.
Settings
The Settings charm is an application-aware settings menu. Need to configure your program? Just go to the settings charm! Not terribly ground-breaking, but a nice touch and a good item to round out the Charms menu.
So, What’s The Problem?
The Charms bar has a few issues. The most grievous is the fact that, once again, it’s tied to the Modern UI. On the desktop, the Charms bar does nothing but get in the way. Nothing about the Charms bar is intrinsically tied to the way the Modern UI works, yet Microsoft has forbidden traditional applications from accessing it.
Additionally, Microsoft has done a very poor job educating users on what it does. Some of the names are confusing, and going into the menus doesn’t really help clarify things. That’s not to say that people can’t learn. We learned what these hieroglyphs mean:



What Microsoft forgets is that we find these to be “intuitive” because we all learned what they mean years ago. What about the word “Start” makes you think “my programs are in here?” What does the silhouette of an apple have to do with shutting your computer down? What is that circle icon even supposed to be? We know these things because we were told. There really needed to be a plan in place to educate people on the use of the Charms bar. But instead of doing a little outreach, they’ve killed one of the most innovative features of Windows 8.
Blinded By Dollar Signs
You may have noticed that none of these issues are really that big of a deal if you use Modern UI applications. So why wouldn’t developers adopt the Modern UI the way they adopted new GUI Libraries in the past?
To install a Modern UI application, it must be downloaded from the Windows store.
That right there is what killed Windows 8. Microsoft saw how much money Apple was making in its App Store and thought “I want that.” What Microsoft failed to realize is that Apple has always carefully curated the hardware and software of its ecosystem, and this is something Apple’s customers like. Windows does not have this culture.
While not as free as Linux and friends, Windows has always been an open platform. Sure, the operating system itself is closed, but it does not restrict what you can accomplish. It doesn’t impose its will, it provides tools and a workshop and tells developers to have fun. This all changed with Windows 8.
To get an application into the Windows store, you must first get an account with Microsoft. This account costs $99/year for companies, and $19/year for individuals, but any price of admission immediately alienates a class of developers. This is actually the catalyst that fueled my switch to Linux. One can’t really create an open source application using the Modern UI, because any fork would have to be submitted to the Windows store as well, costing that person money.
Assuming you are undeterred, and get the account, you must submit your application to Microsoft for approval. Microsoft can at this point reject your application, or force you to change it. Prior to Windows 8, there was no approval process; anybody was free to ship any program they wanted. Microsoft didn’t know or care what you did to your own computer.
Finally, Microsoft gets a cut of your profits. This was the real issue for most major software firms. They had a choice: deploy a Modern UI application through the Windows store and share their profits with Microsoft, or continue to deploy traditional desktop applications and keep 100% of the profits.
This was not a difficult choice. Unlike with Apple and their App Store, Windows users do not expect to get their software from the Windows store; they are used to getting their software via different methods. Windows users did not flock to the Windows store, and those that did look found nothing but garbage. The backlash against Windows 8 was severe and immediate. Unfortunately this vicious cycle could only end with the death of the innovative features of Windows 8. The real losers here are the users.
Change is hard, and I can appreciate that people might not agree with me. But people weren’t even given the chance to give the changes an honest shot! No user can be blamed for forming the opinions that they have; the Start Screen, Modern UI, and Charms Bar were dead on arrival. They were sacrificed on the altar of greed for a quick buck.
I, for one, mourn their loss.
What Is The Deal With Open Source?
So maybe you’ve heard talk of something called “Open Source”. Maybe a friend or family member told you about it, or you heard about it on the internet. Maybe you use it. Usually, when somebody professes the virtues of open source, they speak of it as this great force of good protecting the masses from the Evil Corporations. If Superman were a piece of software, he would be open source, here to protect you from Lex Luthor’s new giant mechanized monster: The Micro$oft Abominatron.
The point is that these arguments are emotional. Conventional wisdom would tell you that this is because Computer People are bad at explaining things. The fact is that open source is a difficult concept to internalize. It seems ridiculous; if your application is so great, why put it out there for free for anybody to use or modify? Why not sell it and become the next Bill Gates?
There are good answers for these questions, and in this post I’d like to discuss some of them. This is a post for the lay person, and as such I’ll keep the technical jargon to a minimum. That said, when you speak in analogies, little important details can get lost in translation. Please bear with me. That said, let’s get down to it.

So, what is the deal with Open Source?
A Brief Overview
An open source application is an application whose source code is freely available to modify. These applications are licensed under one of various open source licenses. These licenses are similar to the one you click “accept” to when you install a program. The license describes the restrictions on what you can do with the open source application. There are very permissive licenses, such as the MIT and BSD, where they basically say “do what you want with this software, just give credit where credit is due” (allowing code to be used anywhere).
There are also very restrictive licenses, such as the GPL license which basically says “you may do what you want with this software, so long as any derivative works are distributed under this same license” (effectively ensuring the code is only used in other open source projects).
Whatever license an open source project chooses, the intent is the same. The code for the application is freely available somewhere, and you are free to use the code for the software in your project, so long as you respect the terms of the license. You could take an open source application, change its name, and release it as your own if you wanted to. Just make sure you respect the terms of the license. However, this isn’t typically done for various reasons.
While open source means that the code is free for anybody to access, this doesn’t mean that just anybody can make changes to the original project. Typically the group behind a project will regulate who can make changes, and how changes get made. Some organizations are quite open about accepting changes from the community. Some don’t accept changes at all. In this way, the “owner” of an open source project controls the software, and maintains the quality of the product.
Why Should You Care?
At this point you may be thinking “that sounds all fine and good, but why should I care about any of this?”. It does seem awfully warm and fuzzy, but there are some very good reasons you should care.
Money
The most obvious reason is money. Suppose you want to type a document. You’d need a word processor, the obvious choice is Microsoft Word. So you go to Microsoft’s online store and search for Word. You click on the link for Word and see that it costs $109.99. Just for Word. The entire Microsoft Office bundle costs $139.99. They will also allow you to pay them $99.99 every year for Office.
What if I told you that there was an open source office suite called LibreOffice that you could download right now for $0? LibreOffice can do everything office can do, but costs nothing. I use it for all of my word processing needs, and I can tell you I will never pay for another copy of Microsoft Office ever again.
Don’t want to spend $19.99/month for Adobe PhotoShop? Download GIMP for free. Don’t want to spend $119.99 for Windows? Download Ubuntu for free. The list goes on and on…
Respect
The very nature of being open source means that the makers of software need to respect the community. Recently, Microsoft released Windows 8. Windows 8 brought with it a whole new user interface. This new interface hasn’t been a huge hit with the consumers, but Microsoft knows that it is free to do whatever it wants because we’re stuck with them. There is a lot of software that only works on Windows, and with Microsoft being the only legal source of obtaining Windows there’s not much we can do. It’s either Microsoft’s way or the highway. Not so with open source.
Any open source project has a third option: Fork. “Forking” an open source project means to make a copy of the source, give it a new name, and begin developing it on your own. Much like a fork in the road, the old project keeps going on its own, and the new project bears off into a new direction. Forking an application successfully is a very tall order. The old project is seen as the “definitive” version, with an established user base. To fork an application, you have to prove that your version is legitimate. Just because you forked a respected project doesn’t mean you get that project’s userbase; you must build your own user base. (this is what prevents people from “stealing” your project. If they fork your project, and the fork surpasses your version, that means they’ve added value you haven’t)
This happens often in open source. Sometimes the two forks coexist peacefully. Sometimes the fork dies, and the original regains any lost users. Sometimes the fork surpasses the original. However the cards fall, the community had its say; the better application won. This is a win for the community as well.
Back to the original topic, with this third option of forking, the developers can’t take their users for granted. At any time the userbase could revolt. Most likely, it’s not practical for you to fork an open source project. However, odds are that if your issue is real, others have it as well. Given enough unrest a fork is inevitable.
Transparency
Lately all the talk in the news has been about NSA monitoring. The NSA has been collaborating with various software development firms to code methods into their software to allow them access. Even if you support what the NSA is doing this should concern you. After all, if the access point exists for the NSA, it exists for anybody. Given enough time, hackers will find these access points, and they will gain access.
This sort of thing cannot happen with open source software. Any change that gets made to an open source project is done in the open. Anybody can see the change, and the exploit has a very great chance of being discovered. There can be no back-door dealings with anybody if the house you’re coming in the back of has no walls.
What’s In It For Developers?
All that is great, but I still haven’t answered the original question: why would anybody do this?
Personal Gratification
Starting at the most basic, developers want personal gratification. Maybe they want to feel like they did something good. Maybe they want to feel part of something big. Maybe they want to stick it to the man. Maybe they want to give back to the community. Whatever it may be, it can be a powerful motivator.
Open Source As A Portfolio
Much like an artist, a developer needs a portfolio. Open source software can be a good way to demonstrate knowledge and experience with a programming language or framework. A developer could make a closed source application on their own time, but they wouldn’t be able to show it off for fear of “revealing their secrets”. Meanwhile, developing in the open, you could show a potential hiring manager specific examples of your work. Additionally, being an active contributor on a respected open source application can be a major boon to a resume.
Branching Out
Suppose a developer works at a company exclusively coding in Language X. Let’s call this developer “Brad”. Development is a fluid field; what is the big language today might be nothing a year from now. It is very important to not become stagnant. Unfortunately for Brad, he’s an expert in Language X, he’s barely touched up-and-coming Language Y. Even worse for Brad is the fact that his employer doesn’t care about his professional development. Brad’s job is to develop in Language X, and incorporating Language Y is a large risk that the financial people don’t feel is worth taking. Brad has no choice but to gain experience in Language Y on his own time.
Enter open source. Brad can find an open source project written in Language Y, and contribute. Brad could also start his own project in Language Y if he wanted. Either way, he’s got options. Development is a unique field in that one can reasonably “gain experience” on their own time. One can’t be a doctor, a lawyer, or a school teacher on their own time. But if Brad contributes to open source using Language Y, not only does he become more proficient in Language Y, but he has tangible proof of his experience in Language Y.
Similarly, a developer might have burned out on the technologies they use at work. Open source represents an opportunity to work on a project that excites them. The bean counters at work don’t care what you want to do, but nobody can tell you what open source project you have to commit to. A developer can contribute to a project that excites them, and they are free to move on at any time.
It’s Their Job
Shockingly, companies even pay developers to work on open source projects. For various reasons that I’ll get into later, companies use open source software. The direction of open source projects is often driven by those who contribute, and for this reason companies often hire developers to develop the aspects of an open source application that they care about.
But Think Of The Corporations!
Don’t worry, I’ve got them covered. As I mentioned in the last point, even companies care about open source. Even the tech giants like Google and Apple depend on and contribute to open source.
Using Open Source Libraries and Languages
Software companies often use open source libraries and languages. A library is a small piece of code that does a specific thing. It is not a full application in its own right, but can be critical to making a full application. Think of it like LEGO. If the individual LEGO blocks are a language, and the finished model is an application, then libraries are smaller bits made up of blocks. You assemble these smaller bits, then piece them together with some additional blocks to make the whole model.
Libraries are critical to making applications. Libraries also make up a large portion of available open source software. Libraries using restrictive licenses like GPL and friends don’t tend to make it into closed source software, libraries with permissive licenses like BSD and friends are often incorporated into closed source projects.
Similarly, programming languages themselves are often open source. This allows organizations to add features to a language to suit their needs. This sort of thing would not be possible with a closed-source language.
Outsourcing Development To The Community
Often, companies will open source products. This allows the community to scrutinize the software, adding new features, fixing bugs, and providing various other forms of feedback. This costs a company nothing, but can save it millions in development costs. The company can then use this feedback to improve the product. Typically, companies will open source components of a larger project that they sell. This allows them to crowdsource bug fixes and the like while still being able to sell their product.
They aren’t too concerned with the community forking their product because they still remain the “definitive” version, and there is little risk of them losing business.
Alternative Forms Of Income
Some tech companies just aren’t in the business of selling software. Google is one of the largest and most respected software development firms operating today, but they don’t actually sell software. Google is in the business of selling demographics data to advertisers. This puts them in the position of being able to freely leverage open source software to make their products. Google provides the google search engine, which is implemented using a variety of open source and closed source software. All of which is transparent to the users. Additionally, Google provides the Android Smartphone OS, which is based on the open source Linux operating system. Google provides countless other free applications and services using open source, and they can do this because these services allow them to glean more and more demographics data.
Similarly, Apple Computers is in the business of selling devices. Sure, Apple sells software, but most of their revenue is from selling various iDevices. Apple is also another huge contributor to open source. While Google uses open source to implement services (see point 1 in companies), Apple outsources development to the community. (companies point 2) Apple backs various open source projects, and incorporates them into their software. Mac OSX itself is a descendent of the BSD UNIX operating system, an open source operating system. A good example of this model is WebKit. WebKit is a piece of software used to read and display web pages, commonly referred to as a “rendering engine”. Apple is a major backer of WebKit, devoting many developers to it. When Apple deemed it ready, they incorporated it into their Safari web browser. Many other web browsers use WebKit as well, including Google Chrome. All largely thanks to Apple.
Another example of this is Apple’s open-source CUPS printing library. If you’ve ever printed something from a non-Windows computer, you probably have Apple to thank.
What Can You Do?
The final piece of this puzzle is: what can you do to contribute? Open source is a collaborative effort, and every little bit helps. However, being the lay person, you probably aren’t going to be contributing code or documentation. You can still help.
The First Step
The first step is to use open source. Personally, I believe that just using an open source project is contributing. By using it, you are legitimizing the project. You are a real person using this software, somebody actually cares! Given all the reasons I outlined above, this seems like a no brainer.
Secondly, you can spread the word. I’m not suggesting you be that guy who rants and raves about open source; frothing at the mouth about how you should use it or you’re stupid and a Bad Person, and support the “Evil Corporations”. No I’m suggesting that when given the opportunity to tell somebody about an open source application in a socially appropriate way, to rationally tell them about Open Source Project X, and that you use it because of [Logical Reason]. Is your friend frustrated with Microsoft Office? Tell them about LibreOffice. It’s that easy.
A Bit More Dedicated
If you’d like to do more, there are plenty of options. Many larger open source projects have statistics gathering features built into their applications. Things like Debian’s Popularity Contest, and Firefox’s Telemetry. Typically, these features can be disabled, however if you don’t mind a minor loss of privacy, you can considering enabling them.
Open source projects do different things with this data. Some use it to determine what kinds of people are using the software, and what things they use most often. This allows them to focus their efforts on the things that “matter”. Letting projects collect this sort of data allows them to improve the things that you use, and that you care about. This helps them because if they know what people want, they can better provide it.
Some open source projects might sell this data. Some might say this is an unacceptable breach of privacy (I count myself among those who would say that. For this reason I usually disable these features), but the fact is that they do this to get funding to improve the project. If you allow an open source project to sell your demographics data, it will make their data more valuable and help contribute to the quality of the software.
Either way, given the nature of open source, whatever information they are gathering from you is all out in the open for anybody to see. While you may not know what you’re looking at, there are people who do. Since typically only major open source projects do this sort of thing (minor projects don’t have a large enough user base to get any useful/valuable data), odds are almost 100% that somebody has independently reviewed it. A quick google search can tell you what they are gleaning and what it’s being used for. Personally, I take privacy very seriously, and I’d advise anybody to do a bit of research before enabling these sorts of features.
Another good way to help is by submitting bug reports. Nobody likes buggy software, but many bugs are nearly impossible to catch in testing. If you’re using an open source application and you find a bug, tell somebody! Ideally, the application comes with a built in automated bug reporting system. Poke around a bit, and see if there’s a “report bug” button. If so, give it a shot. Along with your message, these systems will send information about your configuration that will be useful to the developers.
Failing that, most projects have an easily accessable bug reporting system, usually this can be found on their website. Go ahead and submit a bug report. Try to be as detailed as possible, but if you don’t know something, don’t sweat it. Even if they can’t duplicate the bug, they know that something is wrong, and what general direction to look.
Giving Back
Finally, if you’re feeling generous, you could donate. I’m not going to name “worthy causes” here, but I shouldn’t need to. Do you have an open source application you really like? Donate to them. Maybe they have an online store, and you can get a T-Shirt or coffee mug. It really is that easy.
